
Using AutoML in Oracle Analytics
Approximately one year ago, I have written a blog post Training and deploying AutoML models in Oracle Data Lakehouse. This blog post was part of my Oracle Data Lakehouse blog series, was focusing on training and deploying AutoML models in Oracle Autonomous Data Warehouse (ADW).
Besides that, the post was also focusing on storing and managing data files in object storage and registering them as external tables in ADW.
AutoML generated models are stored and deployed in ADW as any other OML models. If you want to use these models in Oracle Analytics you have to manually register OML model with Oracle Analytics and use it. There is a small detail regarding the location of data to be used with such a model - data has to reside in the same database where model is deployed. Not to mention, that user has to log into OML Notebooks in ADW and perform the training there.
In the latest, March 2023 Update, release this is no longer needed as Oracle Analytics is now capable of using that same AutoML functionality directly from Data Flows.
Let’s look at example. And let’s start with “traditional” approach. Later we’ll check out how can same example be used with the newest functionality.
Data
Before we start with an example, let’s check select data. Let’s take one that is already prepared and is used more than frequently in these kind of show cases. We’ll use the Boston Housing dataset.
For more information, you can also check out my blog post Housing Price Prediction in Oracle Data Visualisation.
Using AutoML in Autonomous Data Warehouse
Oracle Machine Learning is one of the development tools within Oracle Autonomous Data Warehouse.
Oracle Machine Learning is actually implementation of Zeppelin Notebooks with database. You can use notebooks to create and deploy machine learning models whereby Oracle Machine Learning supports use of SQL, PL/SQL, R and Python. When using AutoML, this is done by using so called Experiments.

AutoML runs experiments (ie. searching for the best model)using Python.
Using AutoML experiments is pretty straightforward. Users are not required to know a lot of machine learning. Basic understanding is probably enough. However, preparing data for machine learning is another story and we are not dealing with that in this blog post. Dataset we are using is already pre-prepared and no additional action is needed in that regards.
AutoML starts by creating an experiment.

In the beginning, besides experiment name and comments, a database table with data for model training is selected. In this small experiment, HOUSING table is selected.

Once database table is selected, parameters like predictor, case id and prediction type are selected. In our example, attribute MV is predictor, case ID is column IDX and predition type is already selected based on the predictor selection.
 .
.
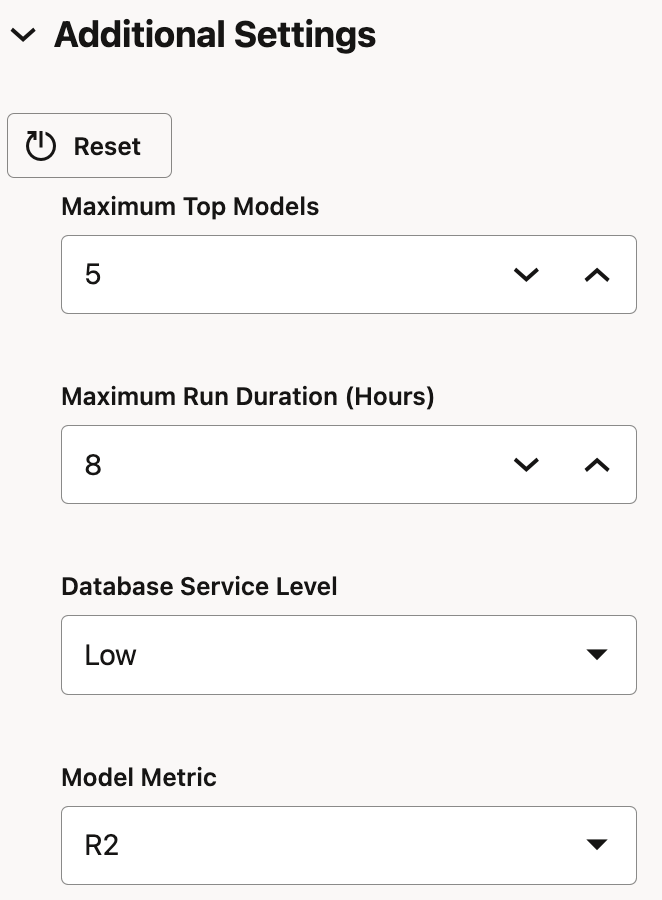
There are some other Additional settings, which can be optionally set. For example, R2 is selected instead of Mean Squared Error as model metric.
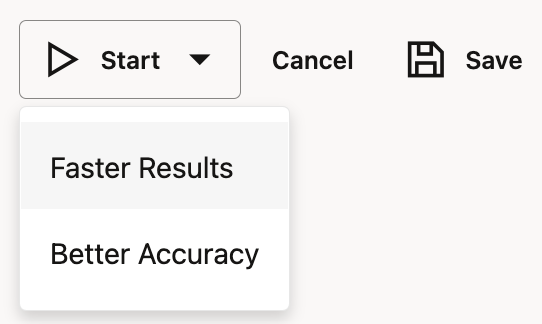
This is basically it! AutoML experiment is ready to be started. There are two options how you would like to run the experiment, Faster Results or Better Accuracy. Choose one and just start.
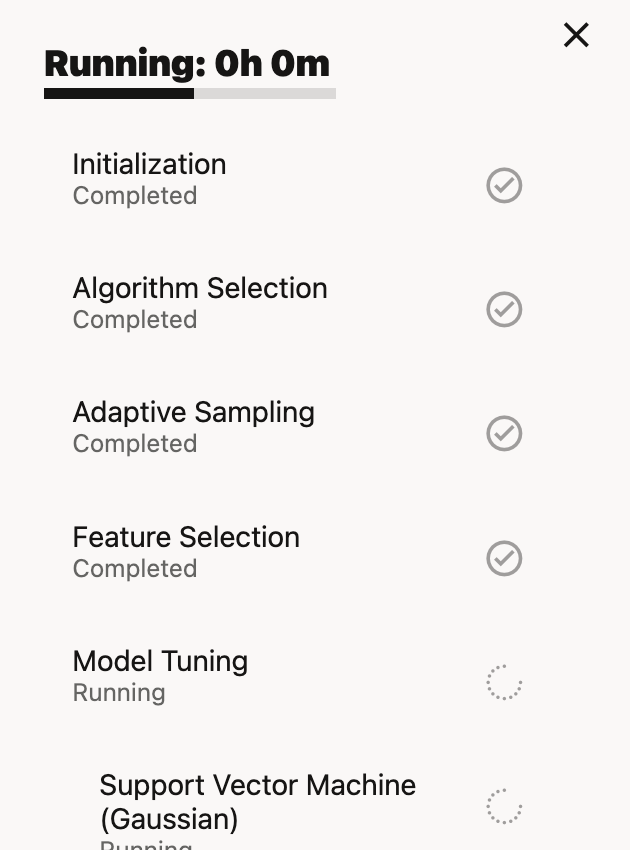
Based on the setting, AutoML experiment will run. Progress can be tracked in Running window.
In the main page, you can monitor results of models run and tested in the Leader Board.
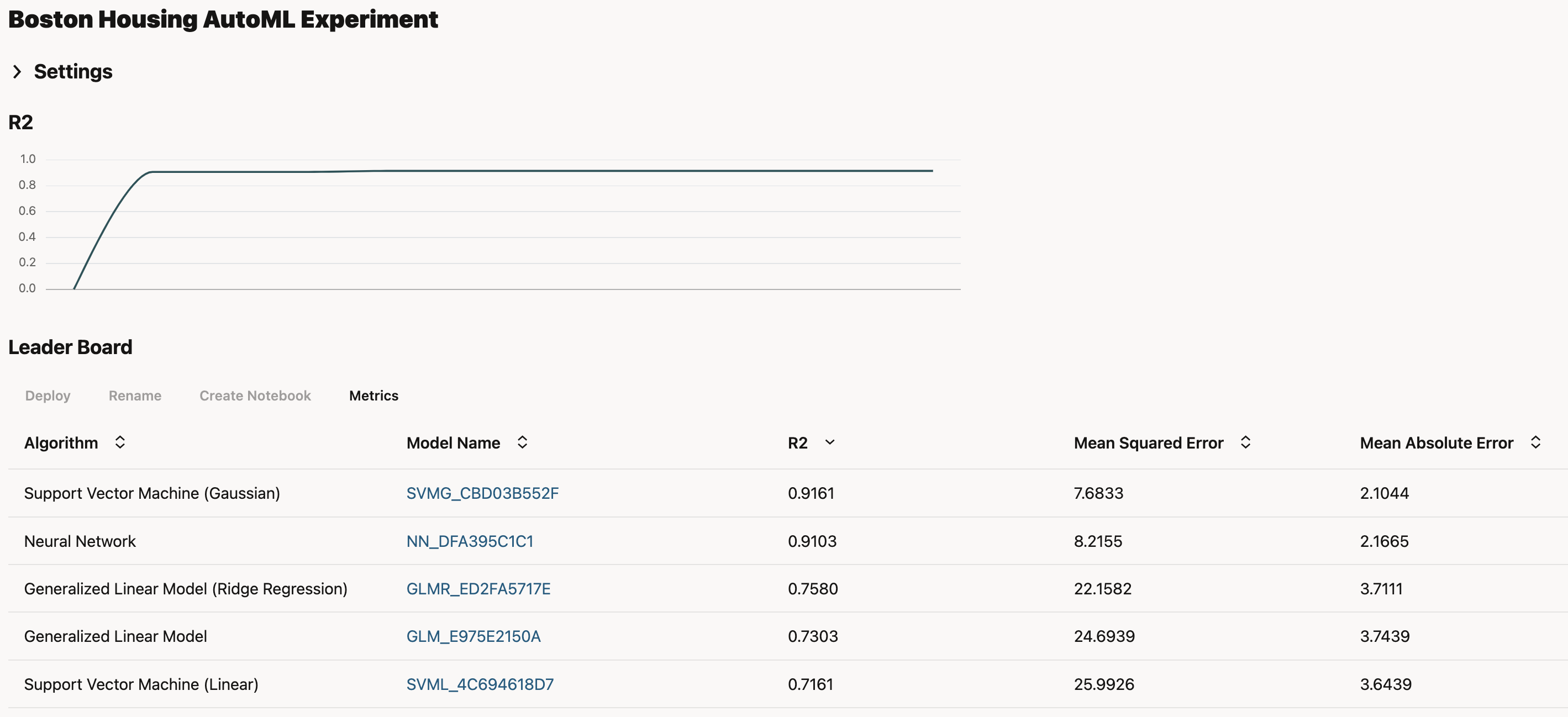
Once done, you can check the model details. In this example, you can see which attributes have the most important impact on prediction.

For easier understanding which model was selected as the best, model has been renamed into THE_BEST_MODEL_FOR_HOUSING.

Let's check code generated. This can be done simply by creating notebook from selected model.
Notebook is generated and it can be opened in Zeppelin Notebooks.
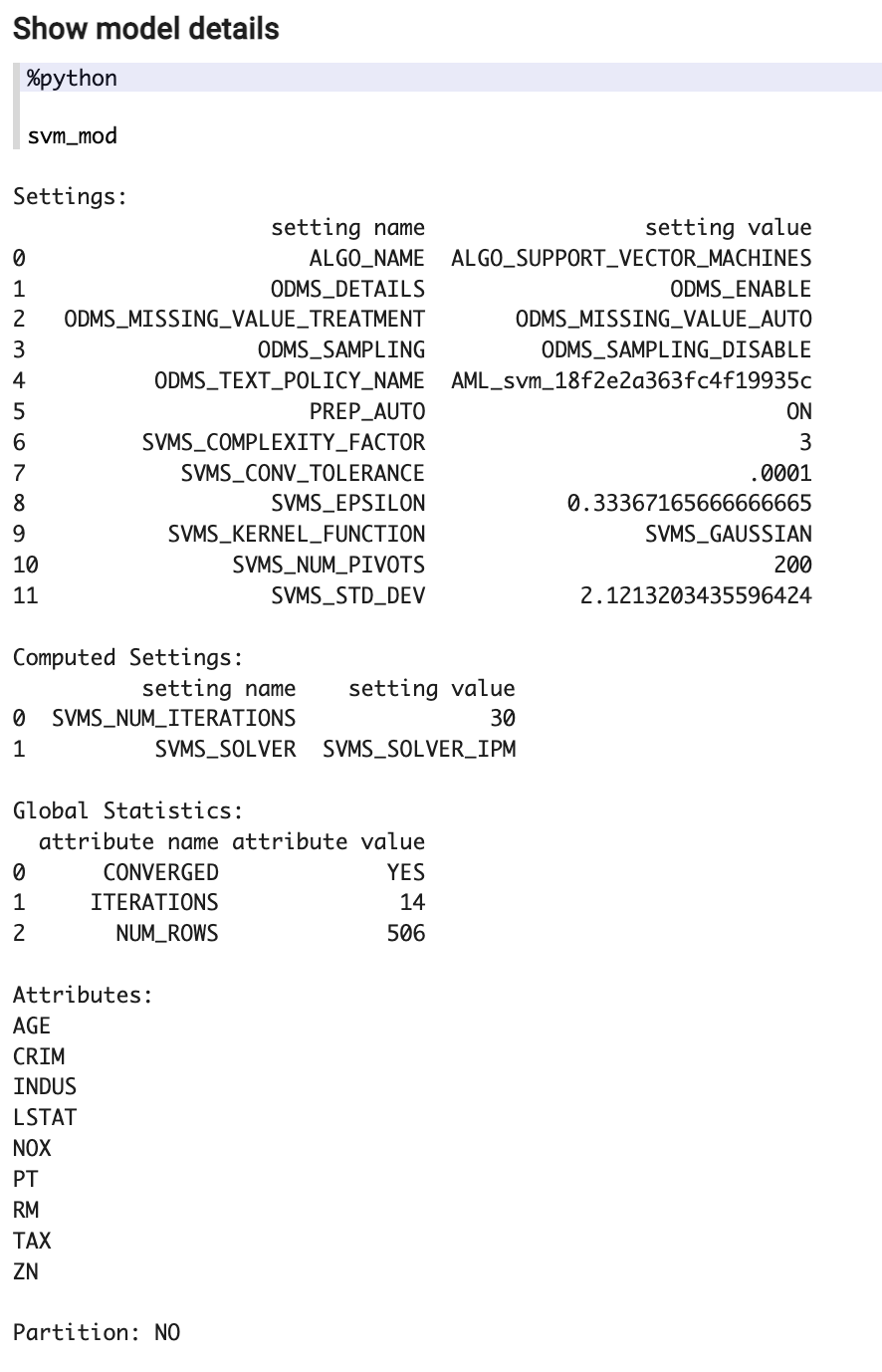
Model has been generated in Python. OML4Py is using transparency layer above OML4SQL so all results are basically running on top of "old-fashioned" Data Mining (of course much improved). So the results are presented as if you were running same model using OML4SQL.
Registering AutoML model with Oracle Analytics Cloud
When OML model is created in ADW, it can be registered with Oracle Analytics Cloud.
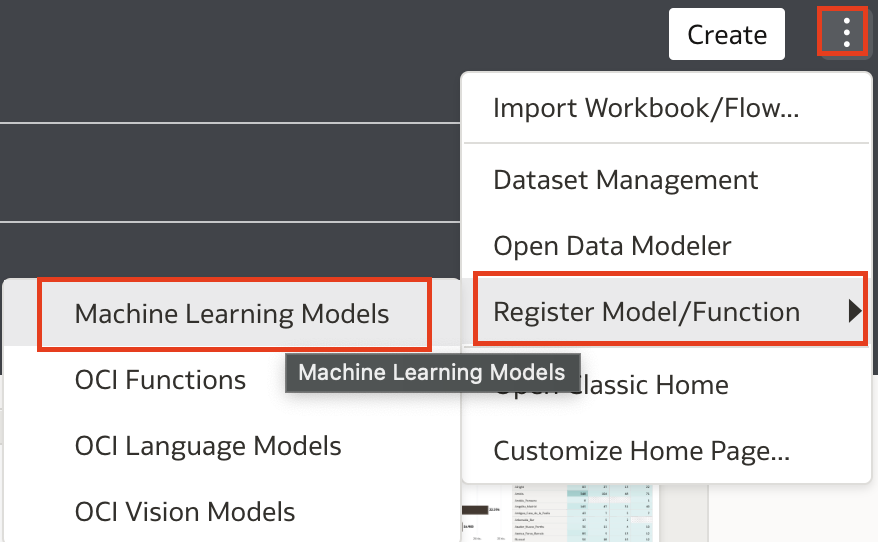
Wizard driven process drives registration of machine learning model with Oracle Analytics.
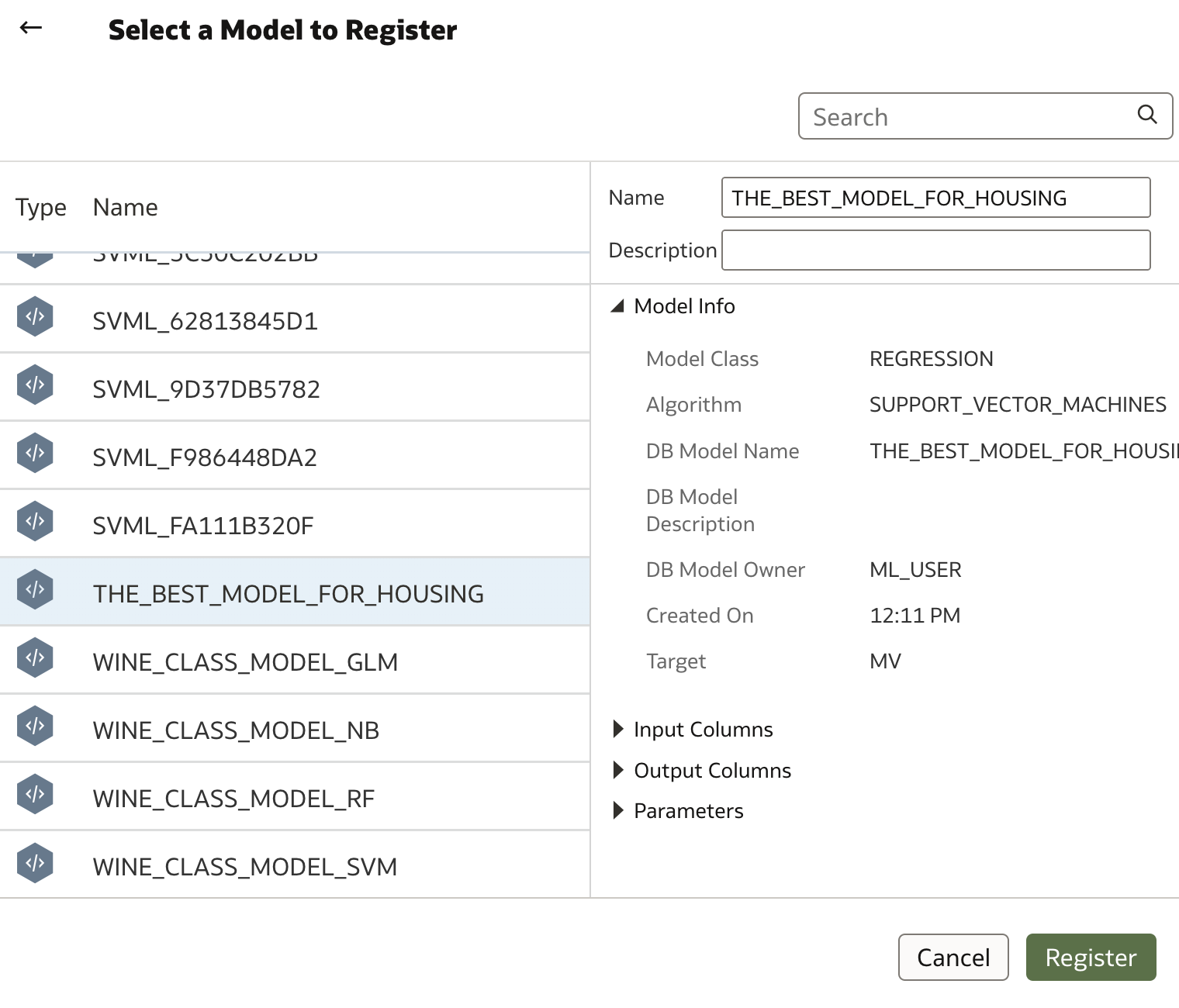
Registered model can now be used in Data Flows as any other machine learning model.
Data Flow itself consists of 3 steps: read data, apply registered model and save predictions.
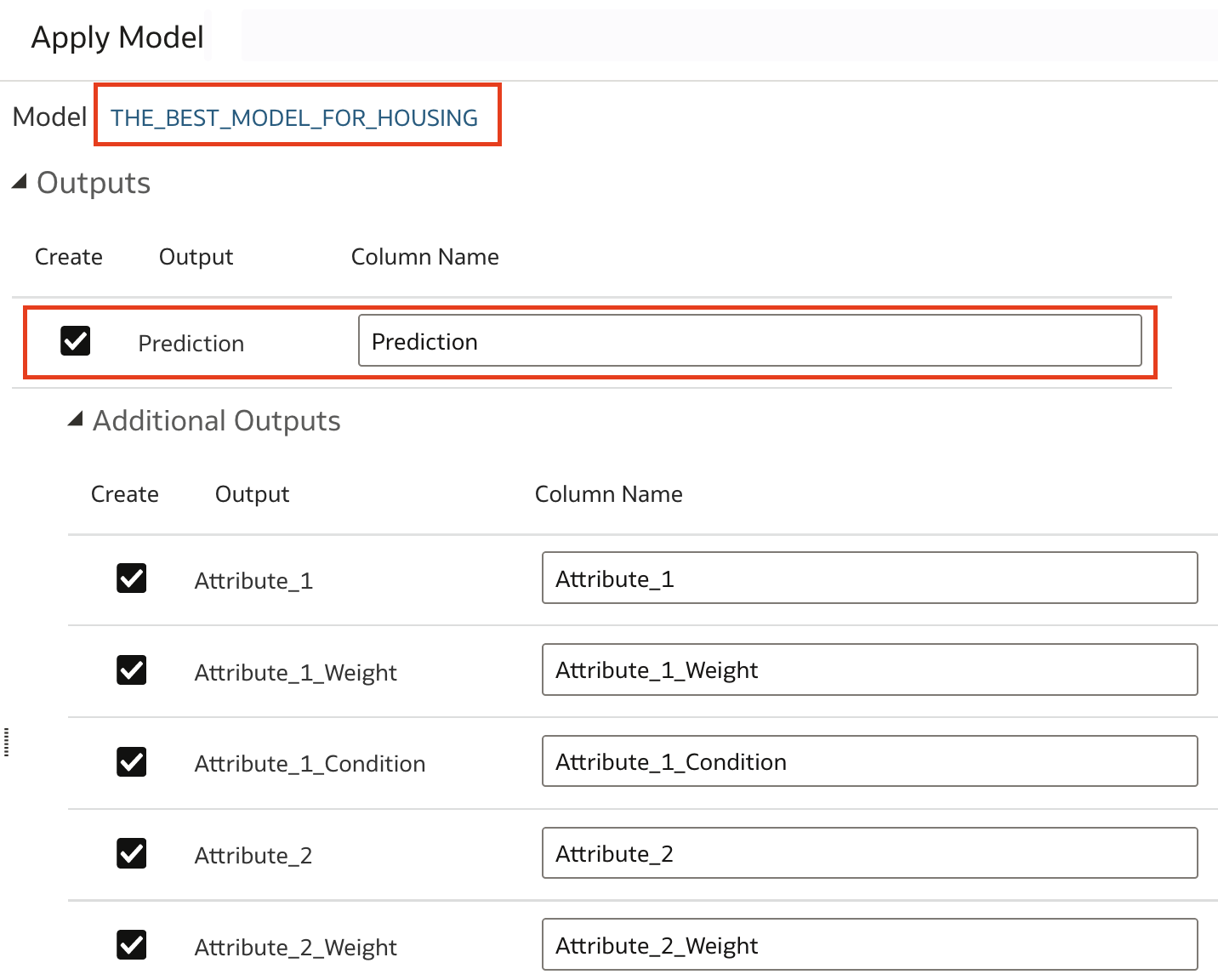
When data model runs it creates data with attributes that were defined as outputs. In case above, this is prediction, and then attributes with weights and conditions as a result of applying selected model.
Deployment of the AutoML models is no different than applying any other machine learning model from ADW. Model needs to be available for registration in Oracle Analytics and then it can be used in Data Flows for performing predictions.
Using AutoML from OAC Data Flows
The process described above is a bit long and involves quite a lot of steps, having in mind that machine learning process is automated.
We can now use AutoML functionality from ADW directly by using AutoML step in Data Flows. Data Flows have additional step called AutoML. Using this step, AutoML really becomes what the name suggests, automated, and can be used by any (business) user from Oracle Analytics.
In the example below, I am using the same dataset as above, the Boston Housing dataset Boston Housing dataset.
As already mentioned, AutoML that is used in OAC is currently using AutoML in ADW. When using AutoML in OAC, then OAS connection to ADW must use a database user with role OML_Developer. It is also required that this user is not admin user.
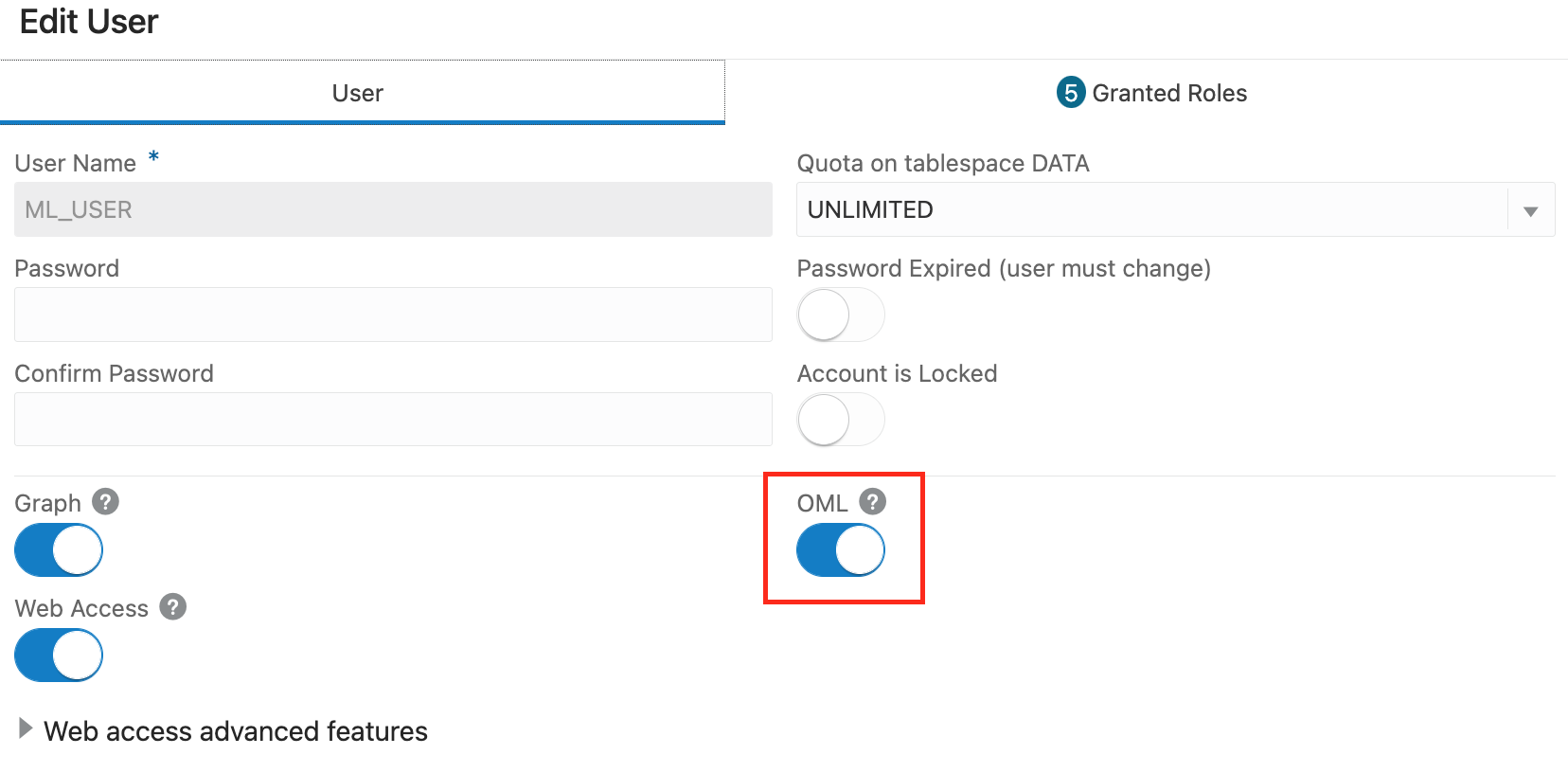
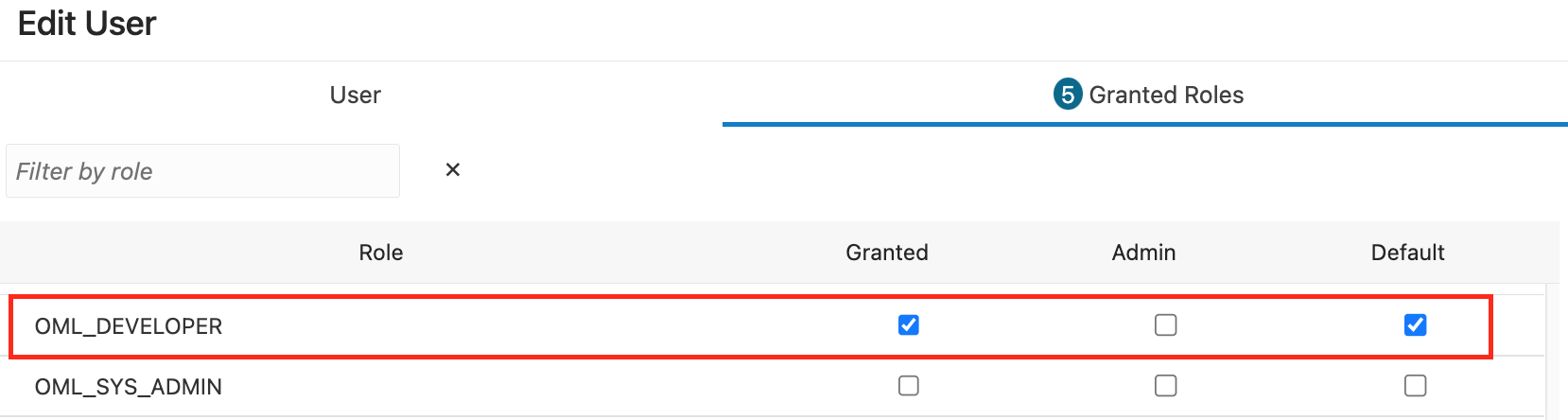
When database user is properly created/updated in ADW, a new connection (if not yet created) is created:
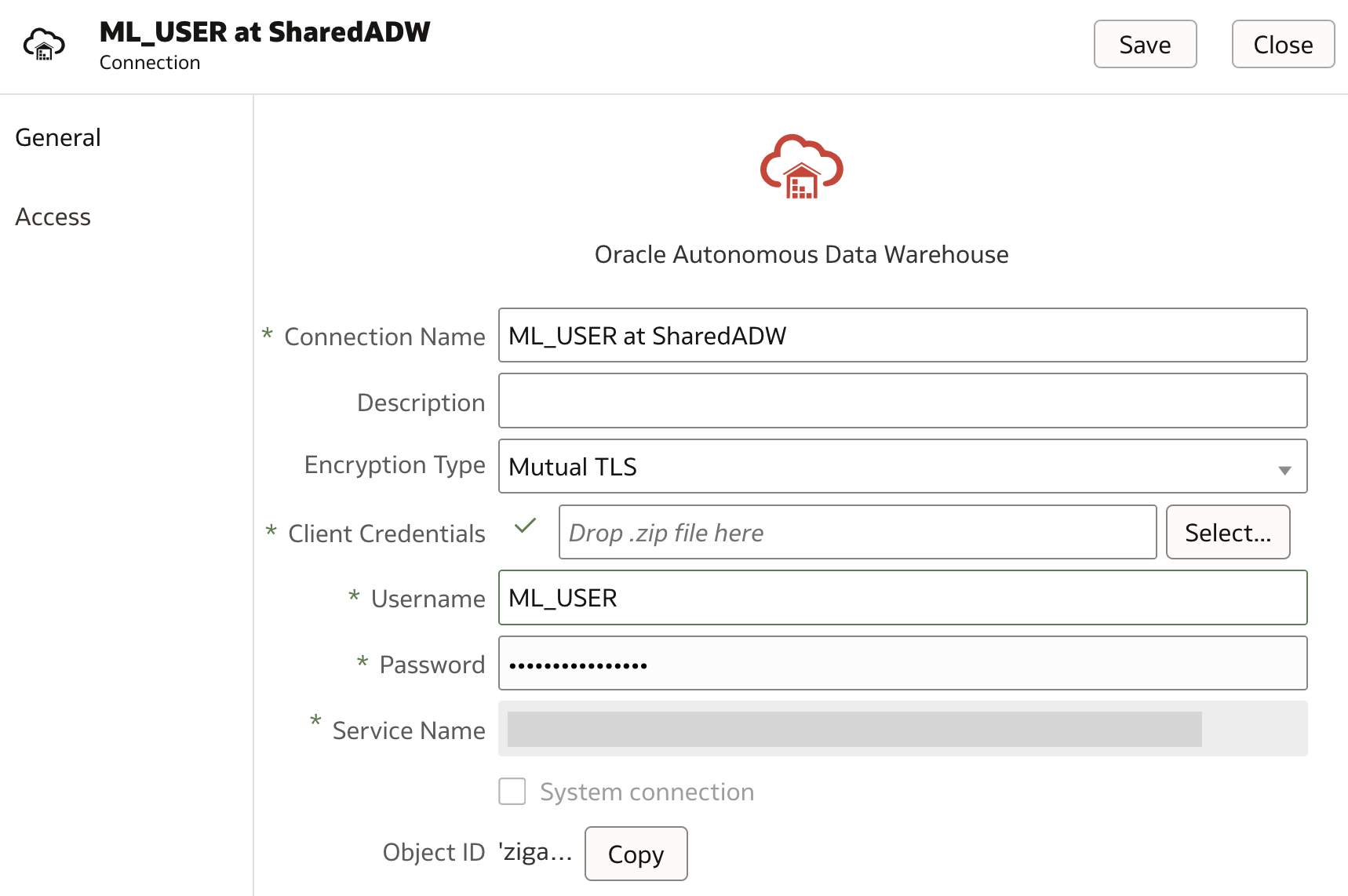
Using the new connection to ADW, training dataset is created, ie. BOSTON_HOUSING dataset.
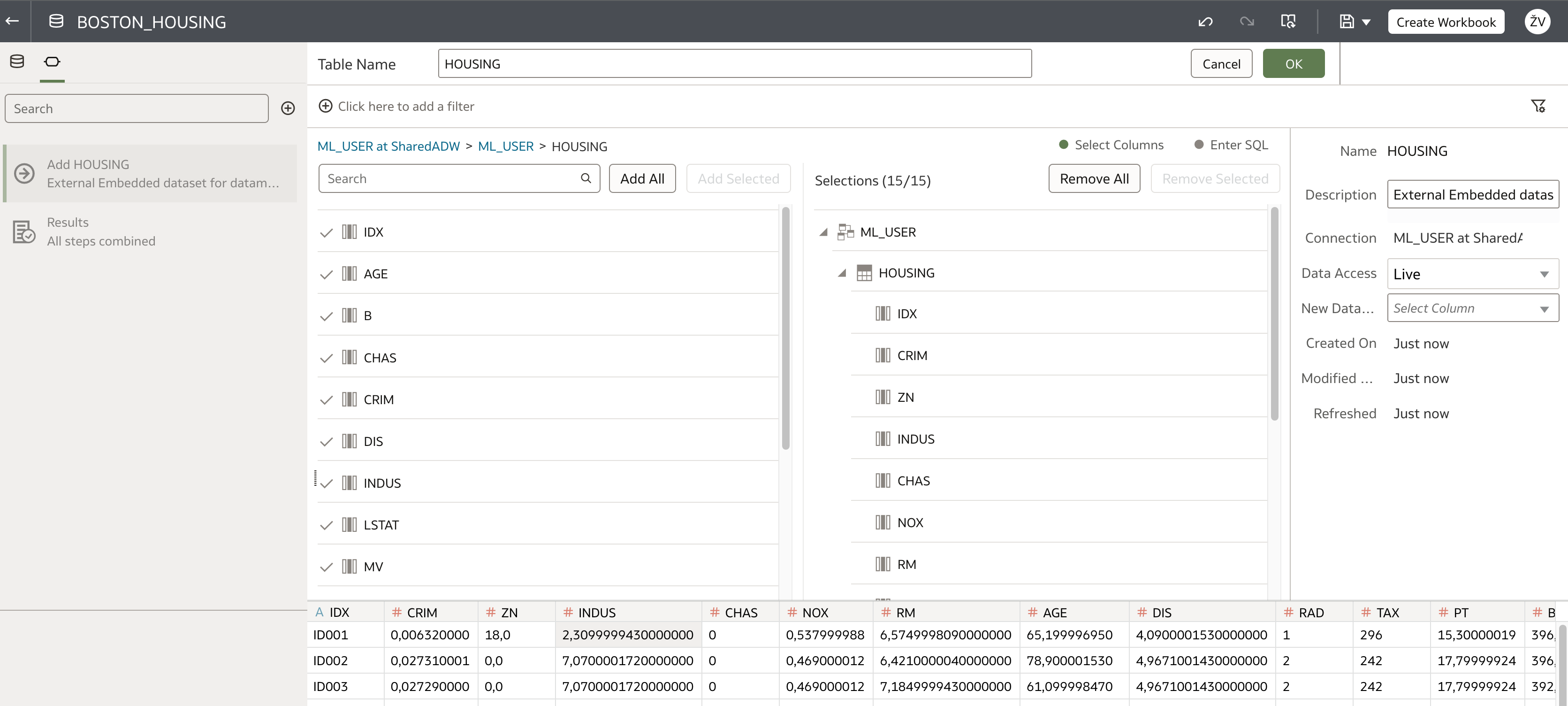
When data is prepared (in this example no preparation steps are required), a new data flow using AutoML step is used. This functionality is new and is available in March 2023 release.
Begin creating a new data flow using newly created dataset. Select AutoML step in the 2nd step in data flow.
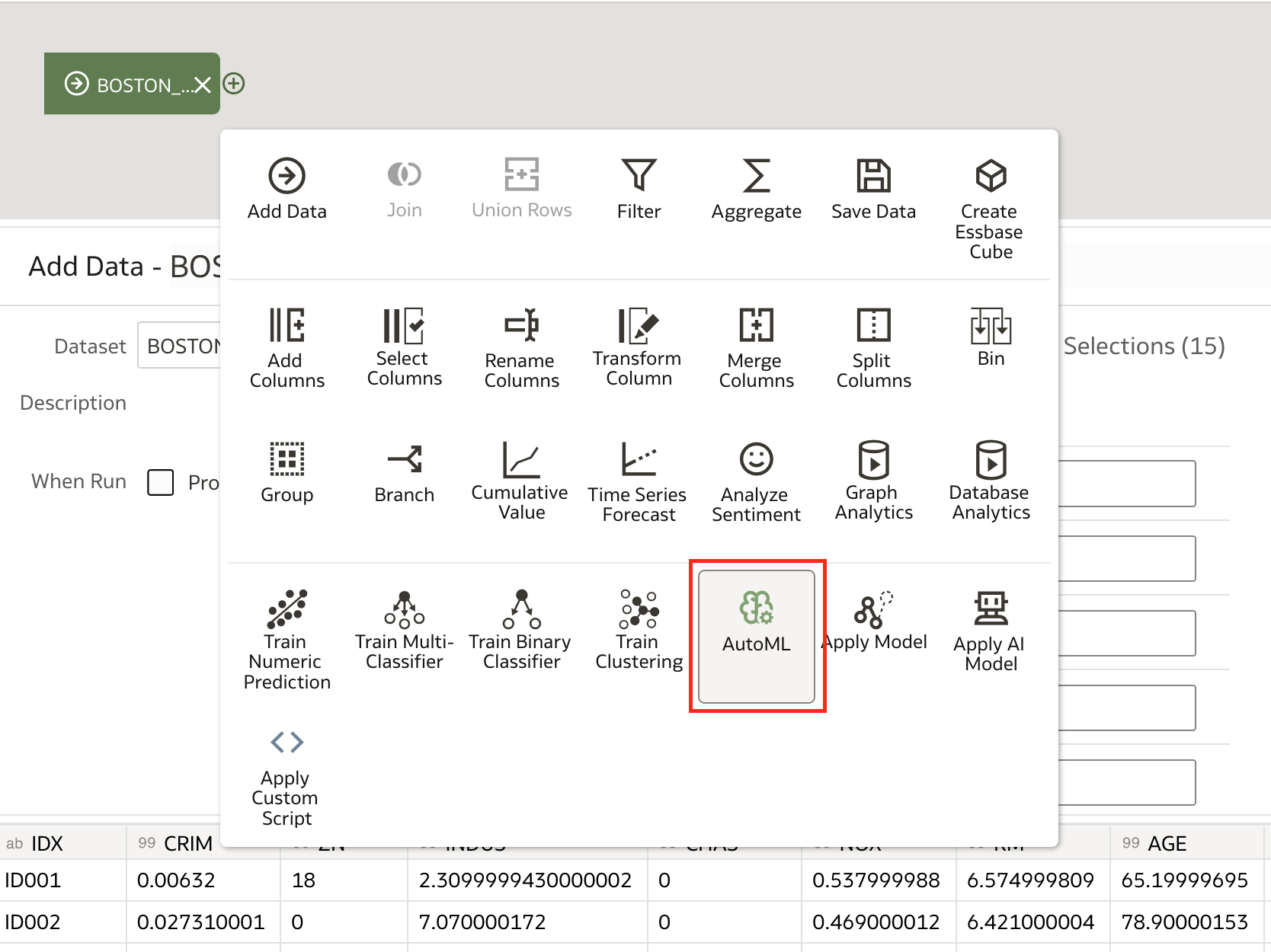
AutoML step is simplified as much as it is possible. First, the target column is selected.
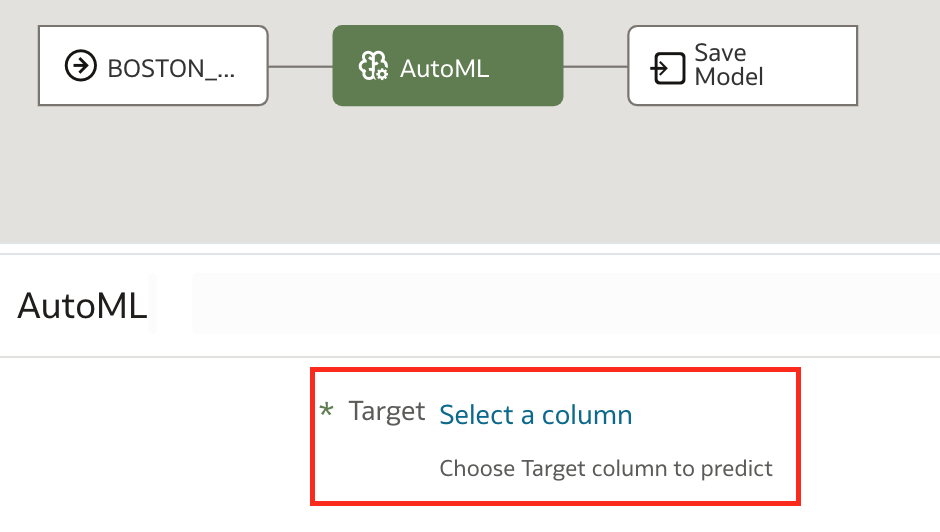
Based on the selection, Task Type is automatically proposed. In our example, target column is a numeric value, hence Task Type proposed is Regression. If this is not the case, and the exercise is a classification problem, this can still be changed manually.
Model Ranking Metric is obviously dependent on Task Type selected. For both Task Types, user can pick one metric from the list.
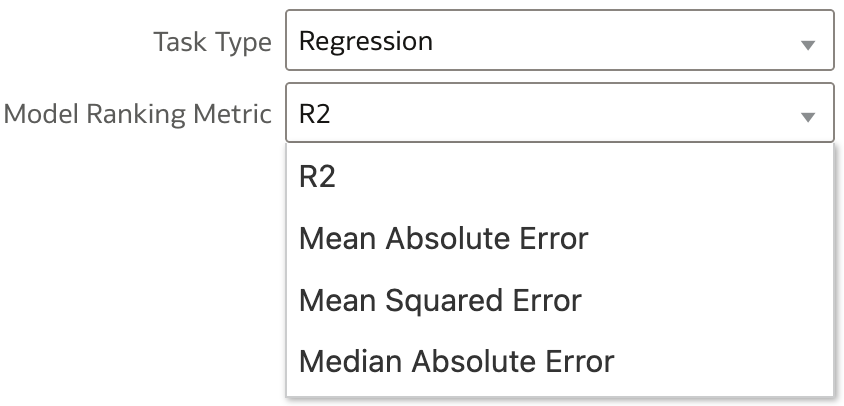
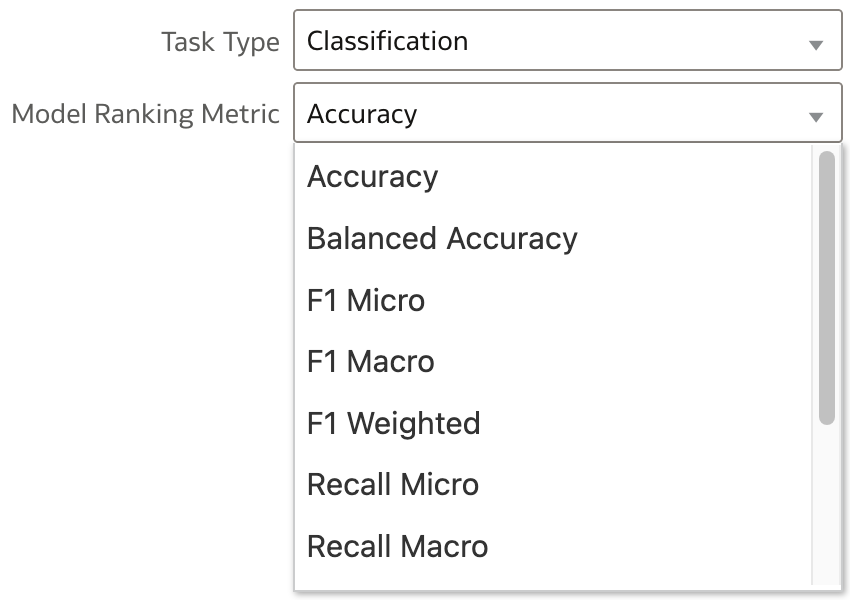
In our example, R2 (R-squared) is selected.
The last step of the data flow is Save Model.
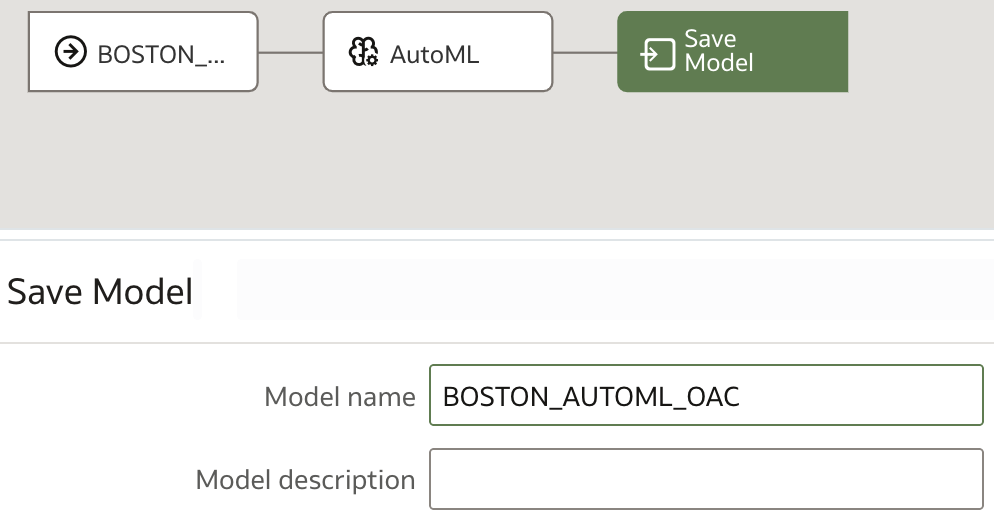
IMPORTANT: In this step, please make sure all characters in Model name are capital and that there are no spaces in the name.
Save and run data flow.
When data flow run completes, check the model under Machine Learning menu.
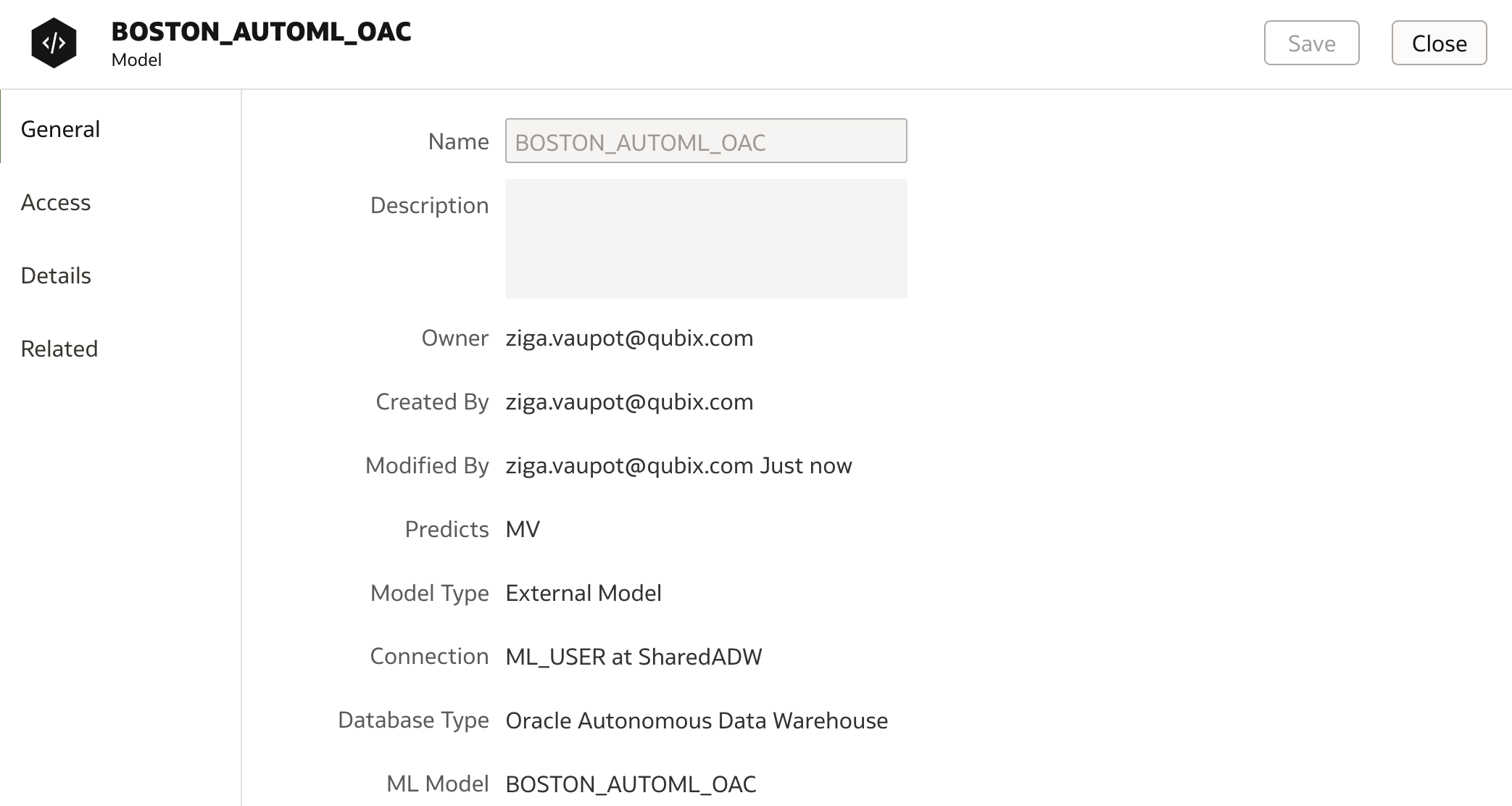
Under the Details tab, we can see that SVM algorithm has been selected and in parameters section, parameters which have been used are displayed.
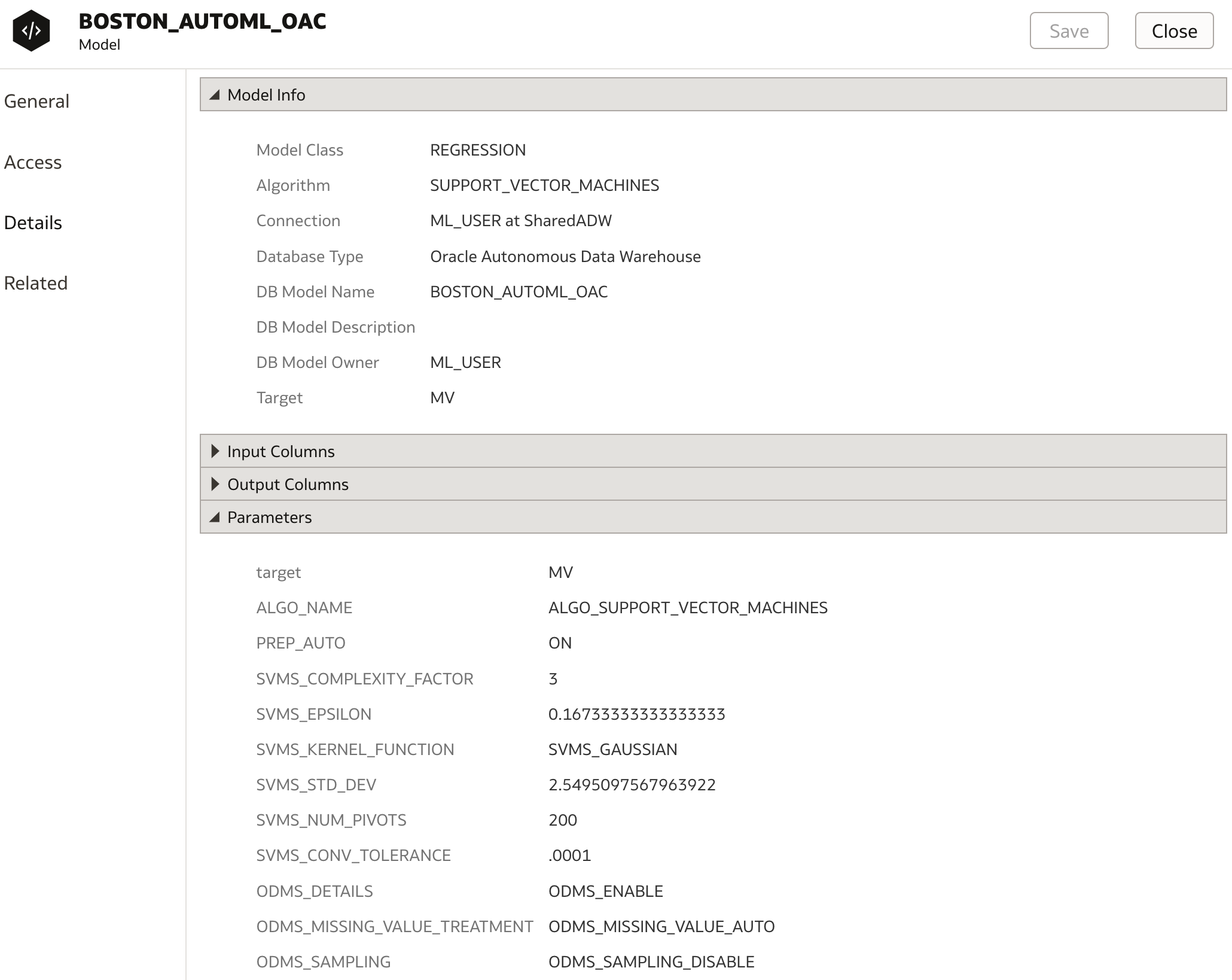
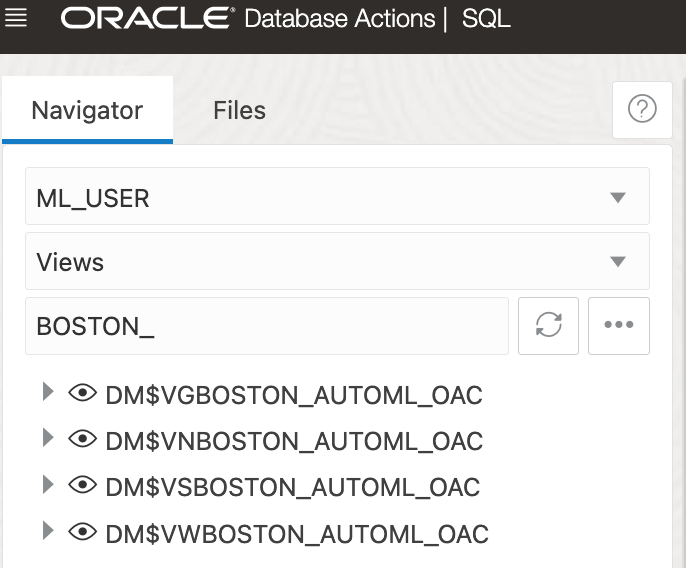
More details are listed under Related tab where the list of generated DM$ views are displayed. These database views contain all relevant detailed information about the model. However I am not 100% sure if the list is correct as it shows views for GLM and not SVM (bug ?!).

These database views can be viewed in database in the schema specified in OAC connection. In my case, ML_USER schema:
Conclusion
Using Machine Learning in OAC was very easy even before. With AutoML support in Data Flows, OAC is enabling business users with even easier option to augment and enrich their analyses. What could be simpler than having Oracle Analytics do all the machine learning work for them.
In this blog post I have presented two options how to use AutoML in Oracle Analytics. However, both are tied to Oracle Machine Learning support in Oracle database (ADW). For some user, who are not using Oracle databases for machine learning, this could be quite limiting.
But luckily, these two options aren't the only options of using AutoML in OAC. For example, machine learning model can be trained in Oracle Data Science Cloud Service using ie. Tensorflow and then integrated and used in OAC. Check out one my future blog posts about this topic.